Service Continuity Policy
Service Continuity Policy
- Verónica Meza
Owned by Verónica Meza
Mar 11, 2016
Athento Cloud users are safe in the knowledge that a Service Continuity Policy is implemented in the face of cloud service downtime.
The Service Continuity Policy features rules, procedures and tools through which Athento can improve its ability to cope with critical system failures and its resistance to the main incident types, taking a preventative approach to securing against possible faults and improving the time within which the team can respond to incidents.
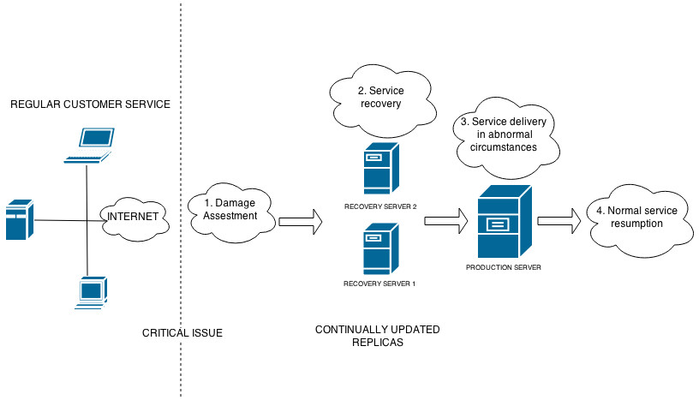
What happens after a system failure?
The Service Continuity Plan is activated. The plan has 4 main stages:
- Initial response: Damage is evaluated and the teams and technical equipment required to handle the incident are identified.
- Service recovery: The service is re-established by providing existing replicas of the system.
- Service delivery under abnormal circumstances: The service has been re-established, but it is not being provided under normal conditions. Provisional measures may include relocating services to another site or using replacement replicas. These are temporary measures to provide a limited service until normal service may be resumed.
- Service resumed under normal circumstances: The original system and/or the replica is re-established in the same conditions (in terms of architecture, band width, etc.) as previously with the original service. That way, normal service is resumed, as before the incident.
Below, you will find the main characteristics of our service continuity policy:
- Athento makes replicas of the functional production instances.
- These replicas are stored in different data centers.
- A replica will always be available for the client to access the service in the event of critical incidents.
- The system has a proxy server that will always redirect to the production server.
, multiple selections available,
Related content
Maintenance and Continuous Improvement Policy
Maintenance and Continuous Improvement Policy
More like this
Cloud Security Policy
Cloud Security Policy
More like this
Athento Cloud Backup Policies
Athento Cloud Backup Policies
More like this
Support plan coverage
Support plan coverage
More like this
Advantages of the Cloud Service
Advantages of the Cloud Service
More like this
On-premise Licensing Model
On-premise Licensing Model
More like this